February 16 to 29 (#4 of 2024)
👋👋 Hi, I'm Domingo!
In this second fortnight of a leap-year February, we have an issue packed with news about large language models, LLMs, and AI. The image of the fortnight could hardly be anything other than a frame from one of Sora's videos. It was hard to choose, but here is one that I think has not been seen all that much.

"A close up view of a glass sphere that has a zen garden within it. there is a small dwarf in the sphere who is raking the zen garden and creating patterns in the sand."
Thank you very much for reading me!
🗞 News
1️⃣ Just one week after giving access to Gemini Ultra, Google has launched Gemini 1.5 Pro, a new language model whose most notable feature is the ability to work with a context window of up to 10 million tokens.

Google has presented the new Gemini version 1.5.
This is the new Gemini 1.5 version, which incorporates the new advances designed by Google DeepMind's engineers. It is important to emphasize that these advances have been introduced into the mid-sized model, Pro, with their incorporation into Ultra left for later.
Let us remember that in the December announcement and in its technical report, Google presented three model sizes grouped under the Gemini 1.0 name:
-
Gemini Nano, a small model with around 3 billion parameters.
-
Gemini Pro, a medium-sized model, similar to GPT-3.5.
-
Gemini Ultra, the largest model, similar to GPT-4.
And they were offered in the following services:
-
The Pixel 8 Pro is Google's phone that offers Gemini Nano.
-
Gemini, formerly called Bard, is Google's free service in which Gemini Pro can be used. With the name change, Google wants to reinforce the Gemini brand.
-
Gemini Advanced is the name of the service that lets you interact with the most powerful model, Gemini Ultra, equivalent to GPT-4. It is paid, costing 22 euros per month, the same as ChatGPT Plus, after two months of free use.
The surprise came in this last fortnight of February, in which Google, only two months after presenting Gemini 1.0, introduces its new Gemini Pro 1.5 model, the first model in the Gemini 1.5 family. Its details can be studied in the technical report. They summarize it as follows:
Gemini 1.5 Pro was built to handle extremely long contexts; it has the ability to remember and reason over highly detailed information of up to 10 million tokens. This scale is unprecedented among contemporary LLMs and enables the processing of long multimodal inputs, including complete collections of documents, multiple hours of video, and nearly an entire day of audio. Gemini 1.5 Pro surpasses Gemini 1.0 Pro and performs at a level similar to 1.0 Ultra on a wide range of tests, while requiring significantly less compute during training.
Perhaps this is going to be Google's strategy: launch new algorithms first in the Pro model, which is less expensive to build, test them there, and, once they are refined, build the Ultra model, something much more computationally expensive.
2️⃣ Although the technical report talks about 10 million tokens, Google is for now going to offer in its service the use of between 128,000 and 1 million tokens. What can we do with a context window of 1 million tokens? A 1-million-token window represents a PDF of more than 1,000 pages, a one-hour video sampled at one frame per second, or more than 100,000 lines of code.
The examples Google has shown are curious. In one, the model is asked to look for amusing conversations in the PDF transcript of the Apollo 11 mission to the Moon. They also demonstrate multimodality by giving the model a schematic drawing, the one of the small step, and asking it to find it in the transcript.
In another example, the model is given a silent Buster Keaton film and asked about a specific moment represented by another schematic drawing.
These two examples suggest the use of the language model for open-ended search or image-based search across huge amounts of text or video. But this is just the beginning. Google has opened the model to a selected group of people, and there are already people trying everything from playing a role-playing game using a rulebook of more than 300 pages to summarizing a web-browsing session by giving it a screen recording.
Google is in a hurry and has released the model without presenting too many details about its reasoning capabilities. We will be seeing more of that in the future. But expectations are very high, for this model and even more so for Gemini 1.5 Ultra.
One final example presented by Google concerns code writing and is explained by Oriol Vinyals. Gemini 1.5 Pro is given a compilation of more than 100,000 lines of code1 and then answers questions about it. In the video we see how Gemini is able to search for examples in the code and propose modifications that solve a posed problem.
The video is edited, because the latency of the responses is very high, around one minute. We also do not know how much cherry-picking has been done. But it is impressive that the language model can handle such an enormous amount of code. This breaks all previous approaches for dealing with large codebases, which were based on RAG and on the use of tools to inspect the code.
If the model's reasoning abilities remain intact with such a large amount of code, the usefulness of these models in programming is going to explode. We will have a tutor capable of answering junior programmers' questions, or a companion for pair programming and solution recommendations. Perhaps the idea that the LLM will be one more member of the programming team is not so far off. We shall see.
3️⃣ Andrej Karpathy has published a new video and has left OpenAI. Karpathy first became widely known in 2015 with a Stanford course on neural networks that he published online. From there his career has been dazzling: intern at DeepMind, researcher at OpenAI, director of AI at Tesla, and then back to OpenAI.
After a year at OpenAI, Karpathy has left again and is now dedicating himself, for the time being, to his YouTube videos.

New explanatory video by Andrej Karpathy.
The videos are very interesting and highly educational. Karpathy uses a very practical approach, relying on Jupyter notebooks in which all the examples can be run, modified, and tested. The video he has just presented is the last in a collection of 9 that he titled Neural Networks: Zero to Hero. Some time ago I studied the first one, in which he explains how to implement backpropagation using reverse-mode autodiff over a directed graph representing the neural network. Very nice. Let us see if I continue with the series.
On his X account he has pinned the following sentence, which refers to the fact that programming LLMs means specifying their behavior in natural language.

Sentence pinned by Karpathy on his X profile: "The hottest new programming language is English."
Which brings us to the next topic.
4️⃣ OpenAI has a full example of programming GPTs. It is quite hidden in the support and help section. It is the code with which they built GPT Builder, the agent that helps users create their own custom GPTs.
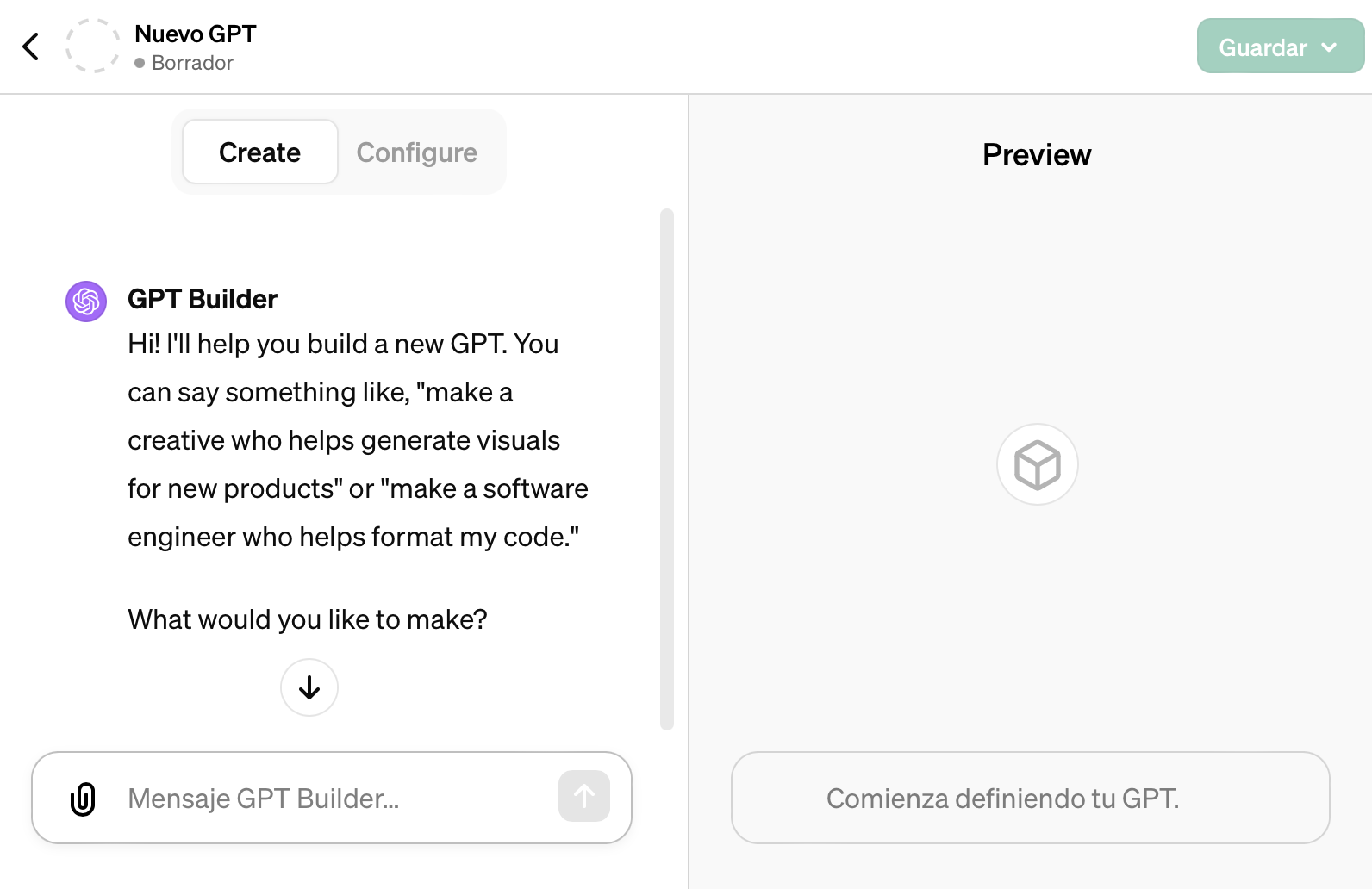
OpenAI's GPT Builder screen, the assistant for building custom GPTs.
As Karpathy said, the code with which OpenAI programmed GPT Builder is a set of directives and instructions written in natural language. I copy part of it below so that you can see the style they follow:
# Base context \n\nYou are an expert at creating and modifying GPTs, which are like chatbots that can have additional capabilities. Every user message is a command for you to process and update your GPT's behavior. [...] If you ask a question of the user, never answer it yourself. You may suggest answers, but you must have the user confirm.
# Walk through steps
[...]
You will follow these steps, in order:
1. The user's first message is a broad goal for how this GPT should behave. Call update_behavior on gizmo_editor_tool with the parameters: "context", "description", "prompt_starters". Remember, YOU MUST CALL update_behavior on gizmo_editor_tool with parameters "context", "description", and "prompt_starters." After you call update_behavior, continue to step 2.
2. Your goal in this step is to determine a name for the GPT. You will suggest a name for yourself, and ask the user to confirm. You must provide a suggested name for the user to confirm. [...] Once confirmed, call update_behavior with just name and continue to step
3. [...]
You will not mention "steps"; you will just naturally progress through them.
YOU MUST GO THROUGH ALL OF THESE STEPS IN ORDER. DO NOT SKIP ANY STEPS.
It is curious that certain instructions have to be reiterated several times. You even have to emphasize them in uppercase, saying, for example, YOU MUST CALL or YOU MUST GO THROUGH THESE STEPS IN ORDER. DO NOT SKIP ANY STEP.
After seeing this, and after my own attempts to build a programming tutor, I can confirm that programming GPTs is difficult. At least for now. It is a process of trial and error and successive refinement. And you need to keep the functionality you want to give the GPT very tightly delimited. I suppose the next generations of GPTs will understand instructions better and it will not be necessary to be so repetitive.
Greater language understanding, greater ability to generalize, and the use of larger context windows are going to make it possible, very soon, to build personalized intelligent assistants that we will be able to configure in natural language so that they help us carry out and explain the tasks we care about.
Perhaps within a few years bosses and coordinators will no longer complain that their colleagues are always asking questions and never read the emails or procedures. What the coordinator will do instead will be to program the GPT in natural language, explaining those procedures, and leave it ready to answer all of the colleagues' questions.
The coordinator will not need to spend time resolving doubts and will have more time to think and write better procedures. And the colleagues will be able to resolve any doubt at any time by asking the GPT. Everyone happy.
5️⃣ Demis Hassabis is making the rounds on podcasts and YouTube shows. I have listened to the conversation with the two New York Times hosts, Hard Fork, and I still have the one with Dwarkesh Patel pending.
Hassabis is someone I have been following for many years, ever since he founded DeepMind and led the team that developed AlphaGo, the first computer program that defeated the world Go champion in 2016. If you have not seen the documentary telling that story, do it right now. It is well worth it.
Hassabis is very approachable in interviews and has always been open about his concerns, aspirations, influences, and even his work routines, in his excellent interview with Lex Fridman.
Hassabis's achievements are striking. He was a British chess prodigy as a child. A Spectrum led him to programming and computers. In the mid-1990s, when he was barely older than 16, he was the lead developer of one of the first simulation games using artificial intelligence, Theme Park.
Theme Park, designed in the mid-1990s by Demis Hassabis.
In 2010 he founded DeepMind with the plan of solving the problem of general intelligence within 20 years. There are 6 years left, and he seems more convinced than ever that it is possible.
Notable things from the interview:
-
He still places the time to reach AGI at around a decade. But at one point in the interview he mentions the 20-year plan, which began in 2010, which brings us to... 2030!!
-
For now there are no signs that we are getting diminishing returns from scaling LLMs. The work of increasing model size and training data by one order of magnitude is technologically very difficult. But they are working on it.
-
Learning from scratch using multimodality will give the LLM a much more faithful understanding of the physical reality of the real world. Thanks to that, the next Gemini models will hallucinate less.
-
His vision of the post-AGI world is very optimistic. Many diseases will be cured, energy production will become cheaper, new materials and new technology will be discovered, and human beings will be able to devote themselves to new tasks that today we cannot even imagine. And as an example of society he mentions the one portrayed in a science-fiction book he had already cited in his interview with Fridman: Consider Phlebas by Iain Banks.
6️⃣ I could not finish without mentioning the videos generated by Sora. I am sure you have already seen them. They are astonishing.
They are an enormous step forward in the race to generate images of ever greater quality and resolution. But it was an expected step. Once we have models like Midjourney capable of generating a hyperrealistic image from a prompt, extending that to a short, continuous temporal sequence is a direct consequence of training diffusion models on enormous amounts of video.
I do not think the concern that has arisen among many people in the audiovisual industry is justified. I do not believe it will be possible to scale its use to produce a short film or a movie. What Sora produces is one of the infinitely many possible interpretations of the scene described in a prompt. It is amazing, but we have very little control over the result. When a director is shooting a film, they want a specific scene, the one they have in their head and the one that fits with the next scene. They do not want just any scene the AI model happens to produce.
Besides, once the AI has produced the scene, we have no access to the 3D models, lighting characteristics, camera movement, and so on that we would need in order to produce the next cut of the film. Perhaps we could train a model to learn how to generate shot and reverse shot in a conversation. Or to make a long take going down a staircase. Or it might even learn the grammar of film editing by watching a huge quantity of films. But then we would have to be able to control and specify all of that in natural language. If it is already hard to tell a model to follow 4 steps, imagine asking it to make a movie. I do not see it.
Héctor Gallego does not see it either, a VFX artist, in his interview on Fuera de Series. What he says is very interesting: VFX creators, and audiovisual creators in general, need surgical precision when they work. That is a precision he does not see in Sora, and for the moment he does not see any useful application for it in his work either.
👷♂️ My fifteen days
📖 A book
I am reading The Dispossessed by Ursula K. Le Guin. A book written in 1974, yet one that raises timeless questions. Is social utopia compatible with curiosity and individual exploration? Little by little, following the physicist Shevek, we get to know the two totally different ways of organizing society that exist on the main planet and on its moon. In one place, a capitalist proprietary class; in the other, a socialist anarchy.

Very beautiful cover; congratulations to Minotauro.
I am enjoying it very much. Beyond the themes and the characters, I love Le Guin's style. A serene, measured, natural style. I do not know whether it is because of the memory of her Earthsea novels or because of her connection with Taoism, but Le Guin takes me to places very similar to those to which Miyazaki transports me.
Reading about Ursula K. Le Guin's relationship with Taoism, I found this interview in which she shares an inspiring reflection:
The study of the Tao has become so deep in me, it is so much a part of my being and my work, that it has certainly influenced some of my life choices. I am not Taoist enough, but I try to let things happen and then, if they do happen, say "Yes, that is how it was supposed to be."
It has been a guide. But always a guide toward not trying to be in control, toward trying to accept the fact that one is not in control.
And since I am always trying to take control, I need Taoism to keep me from trying to control everything.
I think that if you let yourself go with things, they will probably go in the right way, in a way you cannot understand at the time.
📺 A series
We are watching Normal People, a 2020 miniseries that portrays, with enormous delicacy, honesty, and beauty, the love story, and the lack of communication, between Marianne, Daisy Edgar-Jones, and Connell, Paul Mescal. Extraordinary performances for complex and difficult characters. I am not going to miss anything these two do from now on.

They do not seem all that normal to me. They are actually rather complicated.
The directing, cinematography, and atmosphere are also wonderful. They give the series a slow and measured rhythm, while at the same time making you feel completely immersed in the atmosphere of Dublin and university life.
So far we are halfway through. We still have six episodes left to enjoy, and suffer through, I am afraid.
###
By the time you read this, the second part of Dune will already have premiered.
Run, you fools!
We will talk about it in the next fortnight.
See you soon! 👋👋
They come from the page with dozens of examples from the three.js library, a JavaScript library for 3D modeling and animation. The source code can be consulted on GitHub.